

Apple continues to explore how generative AI can improve app development pipelines. Here’s what they’re looking at.
A little background
A few months ago, a team of Apple researchers published an interesting study on training artificial intelligence to generate functional user interface code.
Rather than design quality, the study focused on ensuring that the code generated by the AI actually compiles and roughly matches the user’s call for what the interface should do and look like.
The result was UICoder, a family of open-source models that you can read more about here.
A new study
Now part of the team responsible for UICoder has released a new paper titled “Improving UI Generation Models from Designer Feedback”.
In it, the researchers explain that existing Reinforcement Learning from Human Feedback (RLHF) methods are not the best methods to train LLMs to reliably generate well-designed user interfaces because they “are not well aligned with designers’ workflows and ignore the rich rationale used to critique and improve user interface designs.”
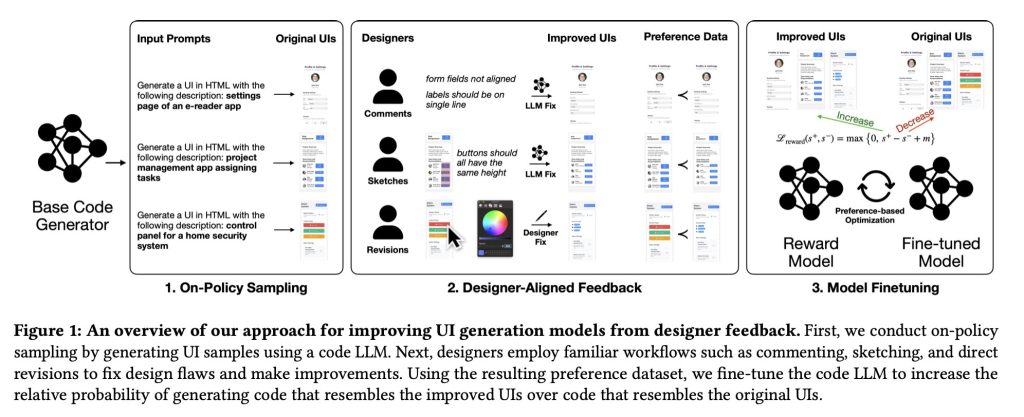
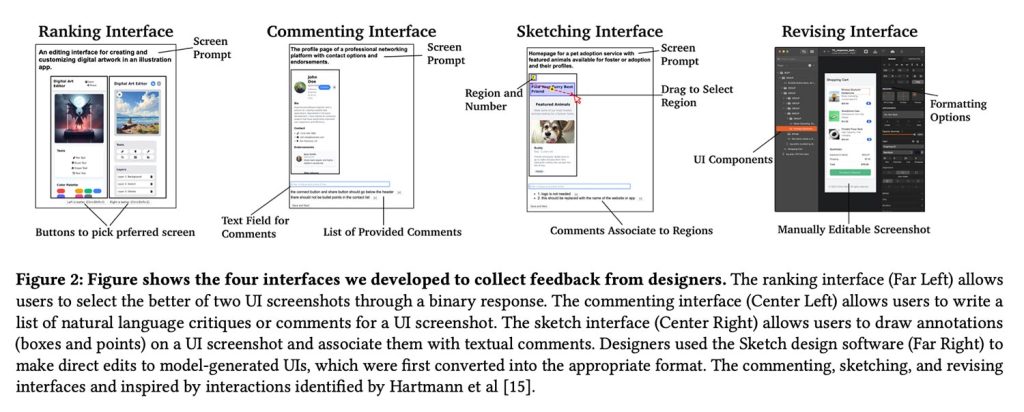
To solve this problem, they proposed another way. They let professional designers directly critique and improve model-generated user interfaces with comments, sketches, and even hands-on edits, then translate those before-and-after changes into data used to fine-tune the model.
This allowed them to train the reward model on specific design improvements, effectively teaching the UI generator to prefer layouts and components that better reflect true design judgment.
Settings
A total of 21 designers participated in the study:
Recruited participants had varying levels of professional design experience ranging from 2 to over 30 years. Participants also worked in various design fields such as UI/UX design, product design and service design. Participating designers also noted the frequency of performing design reviews (formal and informal) in work activities: from once every few months to several times a week.
The researchers collected 1,460 annotations, which were then converted into paired examples of user interface “preferences,” contrasting the original interface generated by the model with the designers’ improved versions.
This in turn was used to train a reward model to fine-tune the UI generator:
The reward model accepts i) a rendered image (screenshot of the UI) and ii) a natural language description (target UI description). These two inputs are fed into the model to produce a numerical score (reward) that is calibrated so that higher quality visual designs lead to a larger score. To assign rewards to the HTML code, we used the automated rendering pipeline described in Section 4.1 to first render the code to the screenshots using browser automation software.
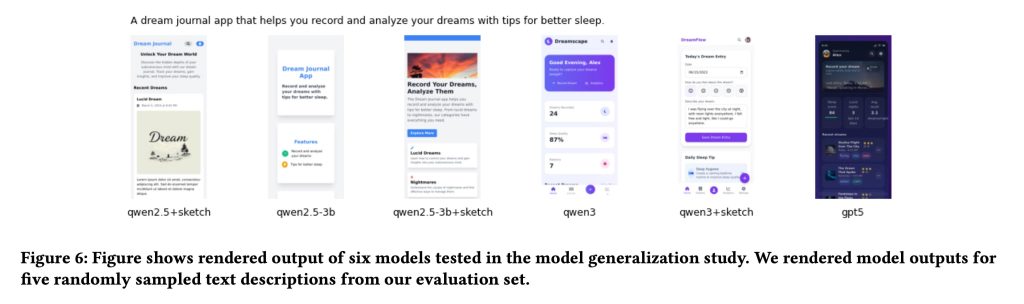
In terms of generator models, Apple used Qwen2.5-Coder as the primary base model for UI generation and later applied the same rewards model trained by designers on smaller and newer variants of Qwen to test how well this approach generalized across different model sizes and versions.
Interestingly, as the study’s own authors note, this framework ends up looking a lot like a traditional RLHF pipeline. The difference, they say, is that the learning signal comes from native designer workflows (comments, sketches, and hands-on revisions) rather than thumbs up/down or simple classification data.
The results
So did it actually work? According to the researchers, the answer is yes, with important caveats.
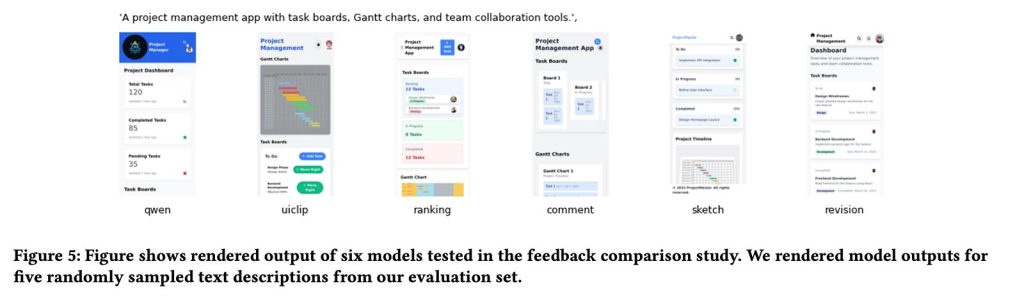
In general, models trained on designer feedback (particularly through sketches and direct revisions) produced noticeably higher quality UI designs than both baseline models and versions trained using only conventional rating or evaluation data.
In fact, the researchers noted that their best-performing model (Qwen3-Coder tuned using sketch feedback) outperformed GPT-5. Perhaps more impressively, it was ultimately derived from just 181 sketch annotations by designers.
Our results show that fine-tuning our sketch-based reward model consistently led to improved UI generation capabilities for all baselines tested, suggesting generalization. We also show that a small amount of high-quality expert feedback can effectively enable smaller models to outperform larger proprietary LLMs in UI generation.
As a caveat, the researchers noted that subjectivity plays a large role in what exactly constitutes a good interface:
One of the main challenges of our work and other human-centered problems is the mastery of subjectivity and multiple solutions to design problems. Both phenomena can also lead to large differences in responses, posing a challenge to widely used assessment feedback mechanisms.
In the study, this difference manifested itself as a disagreement about which designs were actually better. When the researchers independently evaluated the same pairs of user interfaces that the designers rated, they agreed with the designers’ choices only 49.2% of the time, barely a coin toss.
On the other hand, when designers provided feedback by sketching improvements or directly modifying the user interface, the research team agreed with these improvements much more often: 63.6% for sketches and 76.1% for direct modifications.
In other words, when designers could specifically show what they wanted to change, rather than just choosing between two options, it was easier to agree on what “better” actually meant.
For a more in-depth look at the study, including more technical aspects, training materials, and more interface examples, follow this link.
Accessories offer on Amazon
![]()
![]()
FTC: We use automatic income earning affiliate links. More.
